In a previous post I said that Pelagios Commons/Peripleo does not have its roots in the world of scholarship but in the world of computer science - specifically the ideas of Tim Berners-Lee.(1) Now let's concentrate more specifically on what Pelagios Commons/Peripleo really does.
The first
thing that must be clearly understood is that Pelagios Commons/Peripleo creates
no scholarly content and has nothing whatsoever to do with any Classical scholarship. It is strictly a computer science construct and, with a different database, would be perfectly at home in the world of migration tracking, chemical research, or anything else.
Peripleo is simply a
front-end site or data aggregator of a very common type.
Pelagios Commons links
large amounts of data produced by other non-related sites and entities and
subsumes them under a common format. It then
exploits this umbrella format in order to write its own front-end viewing tools
(Peripleo).
Its business
model is exactly like that of Huffington Post and any one of hundreds of
similar sites. Through an agreement with
providers it reproduces their work tout
court. They say that these unpaid
contributors are members of a ‘Community’ but this ‘Community’ is nothing more
than the stable of content providers who give away to Pelagios the fruits of their
labors. The most amusing statement on
the Pelagios website strenuously denies this plainly obvious fact:
Well,
Pelagios provides no original scholarly content.
Pelagios exclusively displays content provided
by others.
Pelagios forces their providers to reduce their own work into a Pelagios format in order
for Pelagios' software to display it.
Peripleo implements numerous search options.
What else
can Pelagios/Peripleo be but an
aggregator/search portal? In fact, if you go to their Peripleo splash page they clearly say 'Peripleo is a search engine ...'. The fact that
their content providers cooperate in the theft of their own labors does not
change the essential nature of the arrangement (This was true for Huffington Post which disguised its essential nature until the moment it went public).
The content providers are said by Pelagios to be members of a ‘Community’. From my many years as a professional computer
scientist I can assure my readers that this type of dishonest rebranding is
quite common everywhere in the online world.
The first step in any internet grift is to give it a
name that expresses the opposite of what it really is.
That it is the contributors who are to do all the work is also obvious from the tools that Pelagios Commons provides:
Recogito This
is an ‘online platform for collaborative document annotation’. But it is not the staff of Pelagios Commons
that’s going to do this annotation (how could they?). It is the contributor, the member of the ‘Community’
who creates this content.
Their Cookbook makes it easy to see who it is who does all the work for Pelagios (hint: not the
Pelagios staff themselves). In every
case the contributors are
responsible for massaging all their data into a form that Pelagios can accept. This is a cost to the contributor of many
hours of uncompensated labor. Pelagios
should disguise this aspect better than they do.
The following picture should make these several relationships clearer.
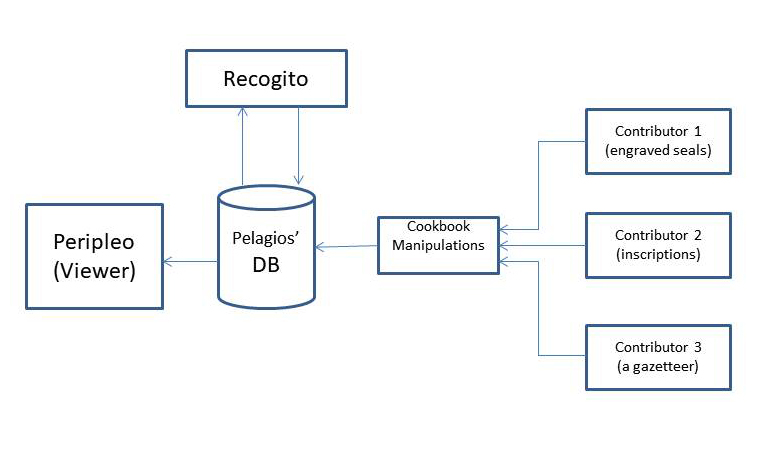
I have claimed that the Pelagios
Commons enterprise creates no content.
Strictly speaking that is not quite true. In fact, Pelagios Commons has achieved the Holy
Grail of academia: it is a perpetual motion machine for producing conference papers and web presentations. If you inspect the list to which I’ve linked
you will quickly see who it is who specifically benefits from the Pelagios Commons
enterprise.
~~~~~~~~~~~~~~~~~~~~~~~~~
Casting doubt on the Pelagios enterprise is
not to deny that some sort of digital structuring of the data that we have from
Mediterranean societies of antiquity would be useful. It would
be useful. But how is that goal to be
attained?
The data that comes to us (or
generated by us) relative to antiquity is of the most heterogeneous forms. Locations, building plans, daily customs,
food stuffs and their hypothesized yields, customs, clothing, trade, etc. Everything of human interest falls within the
purview of scholars of antiquity. This
is a classic data fusion problem. Data
fusion problems arise in environments where a number of sensors of different
types provide data of interest that is to be presented in a uniform view. Such problems arise in the cockpits of
fighter pilots and in very many environmental studies where, again, different
sensors (or the same types of sensors with different capabilities) are used to
gather data which is then to be united, combined or fused into a single point
of view.
Pelagios Commons dimly recognizes that this is the real problem. But they have performed this task
backwards. They start from the
assumption that Linked Data is the solution to everything. Upon that ideology they built a product which is useful
for no one. That’s the essential
problem. The site really isn’t good for
anything because it started ideologically. It did not start by asking what it is that scholars of ancient
societies really need in the form of digital support.
How should the social data from ancient
Mediterranean societies be fused? But, before
that, what does it mean, from the digital point of view, to support such scholars? Particularly in view of the fact that the
scholars in such fields have radically differing interests.
Notes
1) Pelagios Commons here links directly to a discussion of Tim Berners-Lee idea of Linked Data here.

No comments:
Post a Comment